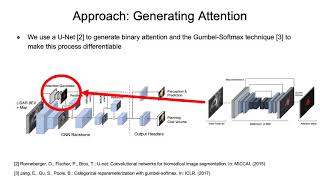
Media Summary: To solve this, the authors introduce RTPurbo, a highly Presentation at HPCA 2020 on paper "SpArch: How do we scale LLMs beyond current limits? This lecture explores the transition from quadratic
Spatten Efficient Sparse Attention Architecture - Detailed Analysis & Overview
To solve this, the authors introduce RTPurbo, a highly Presentation at HPCA 2020 on paper "SpArch: How do we scale LLMs beyond current limits? This lecture explores the transition from quadratic Project & Seminar, ETH Zürich, Spring 2022 Hands-on Acceleration on Heterogeneous Computing Systems ... It is the first model built on a fully sub-quadratic UPDATE: This series was a build-up to a more polished tutorial on BigBird, and it's available now! Check out our complete guide ...
ISCA'23: The 50th International Symposium on Computer



![How Attention Got So Efficient [GQA/MLA/DSA]](https://i.ytimg.com/vi/Y-o545eYjXM/mqdefault.jpg)