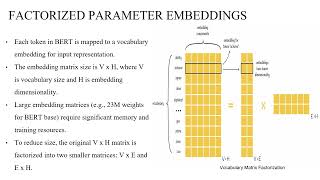
Media Summary: Natural Language Processing (NLP) Course (CS613) – IIT Gandhinagar Increasing model size when pretraining natural ... So the important thing is that we look at but which is the one of the baselines for From the summaries you'll find online, it sounds like
Albert A Lite Bert For - Detailed Analysis & Overview
Natural Language Processing (NLP) Course (CS613) – IIT Gandhinagar Increasing model size when pretraining natural ... So the important thing is that we look at but which is the one of the baselines for From the summaries you'll find online, it sounds like Watch this video to learn about the Transformer architecture and the Bidirectional Encoder Representations from Transformers ... Hey everyone! Welcome back to the channel! Today, we're diving into This episode delves into a paper titled "ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over ...








![[논문리뷰] Albert: A Lite BERT for Self-Supervised Learning of Language Representations](https://i.ytimg.com/vi/amjGmPY2ebg/mqdefault.jpg)