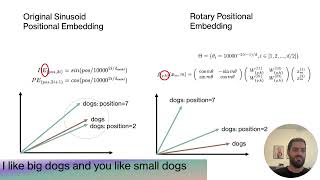
Media Summary: Positional information is critical in transformers' understanding of sequences and their ability to generalize beyond training context ... ... References: RoFormer: Enhanced Transformer with ... points to demonstrate let's build them first for each
How Rotary Position Embedding Supercharges - Detailed Analysis & Overview
Positional information is critical in transformers' understanding of sequences and their ability to generalize beyond training context ... ... References: RoFormer: Enhanced Transformer with ... points to demonstrate let's build them first for each Full explanation of the LLaMA 1 and LLaMA 2 model from Meta, including For more information about Stanford's Artificial Intelligence programs visit: This lecture is from the Stanford ... How do language models maintain a sense of word order across thousands of tokens without breaking physical hardware limits?
![How Rotary Position Embedding Supercharges Modern LLMs [RoPE]](https://i.ytimg.com/vi/SMBkImDWOyQ/mqdefault.jpg)