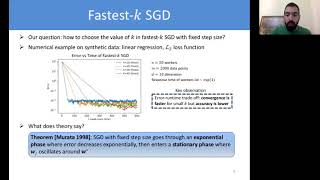
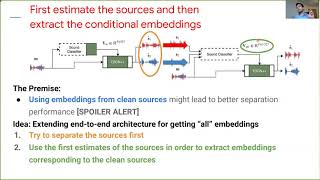
Media Summary: Fatemeh Pishdadian presents her paper titled " Matthew Maciejewski presents his paper titled "WHAMR!: Noisy and Reverberant Single-Channel Speech Separation" for the ... Da-Yi Wu, Hung-yi Lee, 'ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION',
Icassp 2020 Learning To Separate - Detailed Analysis & Overview
Fatemeh Pishdadian presents her paper titled " Matthew Maciejewski presents his paper titled "WHAMR!: Noisy and Reverberant Single-Channel Speech Separation" for the ... Da-Yi Wu, Hung-yi Lee, 'ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION', Jui-Yang Hsu, Yuan-Jui Chen, Hung-yi Lee, 'META Video presentation of the paper: Differentiable branching in deep networks for fast inference S. Scardapane, D. Comminiello, ... Haici Yang, Shivani Firodiya, Nicholas J. Bryan, and Minje Kim, “Don't
Gene-Ping Yang, Szu-Lin Wu, Yao-Wen Mao, Hung-yi Lee, Lin-shan Lee, 'INTERRUPTED AND CASCADED PERMUTATION ... MERL's Petros Boufounos is presenting a talk on "The Computational Sensing Revolution in Array Processing" for the industry ... Andy T. Liu, Shu-wen Yang, Po-Han Chi, Po-chun Hsu, Hung-yi Lee, 'MOCKINGJAY: UNSUPERVISED SPEECH ... Alexander H. Liu, Tao Tu, Hung-yi Lee, Lin-shan Lee, 'TOWARDS UNSUPERVISED SPEECH RECOGNITION AND SYNTHESIS ... SepFormer is a fully attention based masking architecture for source separation. It obtains state of the art results on WSJ0-2/3Mix ... Video presentation for the paper: Tzinis, E., Venkataramani, S., Wang, Z., Subakan, Y. C., and Smaragdis, P., “Two-Step Sound ...
Pu (Perry) Wang presented his paper titled "Slow-Time MIMO-FMCW Automotive Radar Detection with Imperfect Waveform ... Brij Mohan Lal Srivastava from Inria has made a video representing privacy protection ... Johns Hopkins University Ph.D. candidate Xuankai Chang presents his paper titled "End-to-End Multi-speaker Speech ... Video presentation based on the research article titled ``Adaptive distributed stochastic gradient descent for minimizing delay in ... ICASSP:A Novel Split Deep Unfolding Transformer for Pan-Sharpening Video presentation for the paper: Tzinis, E., Wisdom, S., Hershey, J.R., Jansen, A. and Ellis, D.P., “Improving Universal Sound ...
![[ICASSP 2020] Learning to Separate Sounds From Weakly-Labeled Scenes](https://i.ytimg.com/vi/wrvptlOm69U/mqdefault.jpg)
![[ICASSP 2020] WHAMR!: Noisy and Reverberant Single-Channel Speech Separation](https://i.ytimg.com/vi/3tjmYgutM38/mqdefault.jpg)
![[ICASSP 2020] ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION (Speaker: Da-Yi Wu)](https://i.ytimg.com/vi/W3t8FHgV90M/mqdefault.jpg)
![[ICASSP 2020] META LEARNING FOR END-TO-END LOW-RESOURCE SPEECH RECOGNITION (Speaker: Jui-Yang Hsu)](https://i.ytimg.com/vi/goav0eXKPwg/mqdefault.jpg)


![[ICASSP 2020] INTERRUPTED AND CASCADED PIT FOR SPEECH SEPARATION (Speaker: Gene-Ping Yang)](https://i.ytimg.com/vi/RUhkc6ihyYI/mqdefault.jpg)

![[ICASSP 2020] The Computational Sensing Revolution in Array Processing](https://i.ytimg.com/vi/HYbgypGXi-o/mqdefault.jpg)
![[ICASSP 2020] MOCKINGJAY: UNSUPERVISED SPEECH REPRESENTATION LEARNING (Speaker: Andy T. Liu)](https://i.ytimg.com/vi/JlOSyRNFjOw/mqdefault.jpg)
![[ICASSP 2020] TOWARDS UNSUPERVISED SPEECH RECOGNITION AND SYNTHESIS (Speaker: Tao Tu)](https://i.ytimg.com/vi/cnZdfLSqwiE/mqdefault.jpg)


![[ICASSP 2020] Slow-Time MIMO-FMCW Automotive Radar Detection with Imperfect Waveform Separation](https://i.ytimg.com/vi/V1e6iBWhGvs/mqdefault.jpg)

![[ICASSP 2020] End-to-End Multi-speaker Speech Recognition with Transformer](https://i.ytimg.com/vi/Mo2RRNgfU4g/mqdefault.jpg)