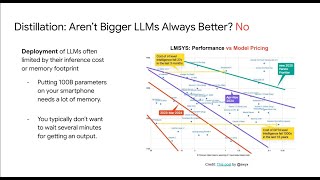
Media Summary: Summer Project for a MSc in Computer Science, UCL. How can we create smaller, faster language models that retain the power of their massive "teacher" counterparts? The answer is ... We all know that ensembles outperform individual models. However, the increase in number of models does mean inference ...
Knowledge Distillation For Nlg With - Detailed Analysis & Overview
Summer Project for a MSc in Computer Science, UCL. How can we create smaller, faster language models that retain the power of their massive "teacher" counterparts? The answer is ... We all know that ensembles outperform individual models. However, the increase in number of models does mean inference ... Finetune tiny LLMs to enable inference using less resources. Link to notebook: ... Welcome! I'm Aman, a Data Scientist & AI Mentor. In today's session, we break down In this video (Part 1 of our Fine-Tuning Series), we dive into LLM
Introduction video to our EMNLP2020 long paper "Lifelong Language Subscribe To My Channel Video Contents: 00:00 Introduction ... In this video, we dive deep into the world of Paper found here: Code will be found here:











![[EMNLP 2020] Lifelong Language Knowledge Distillation](https://i.ytimg.com/vi/t3Ee5fA8mCo/mqdefault.jpg)