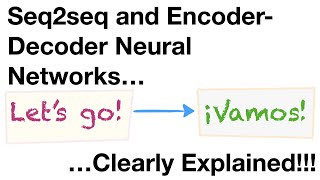
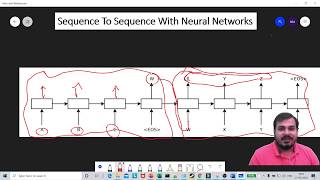
Media Summary: In this video, we introduce the basics of how Neural Networks translate one language, like English, to another, like Spanish. How do you translate a sentence when the input length doesn't match the output length? In this video, we break down the theory ... Sequence To Sequence With Neural Network Research Paper: ...
Seq2seq Lstm Encoder Decoder Clearly - Detailed Analysis & Overview
In this video, we introduce the basics of how Neural Networks translate one language, like English, to another, like Spanish. How do you translate a sentence when the input length doesn't match the output length? In this video, we break down the theory ... Sequence To Sequence With Neural Network Research Paper: ... Resources: This video is a part of my course: Modern AI: Applications and Overview ... Attention is one of the most important concepts behind Transformers and Large Language Models, like ChatGPT. However, it's not ... In this video, we unravel the complexities of the
For more information about Stanford's Artificial Intelligence programs visit: This lecture is from the Stanford ... Learn about watsonx → Long Short Term Memory, also known as LSTMs, are a special kind of Recurrent ... Next Video: Attention was originally proposed by Bahdanau et al. in 2015. Later on, attention finds ... Basic recurrent neural networks are great, because they can handle different amounts of sequential data, but even relatively small ... Introduction Case Study on Machine Translation Applications. This is a step-by-step guide to building a