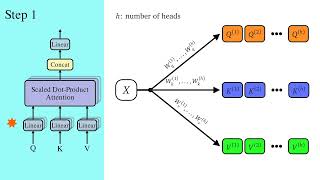
Media Summary: To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... Want to stay updated on the latest AI advancements? Subscribe here: ... In this video, I will first give a recap of Scaled Dot-Product
Sparse Attention Vs Self Attention - Detailed Analysis & Overview
To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... Want to stay updated on the latest AI advancements? Subscribe here: ... In this video, I will first give a recap of Scaled Dot-Product In this AI Research Roundup episode, Alex discusses the paper: 'SSA: Sparse Thanks to KiwiCo for sponsoring today's video! Go to and use code WELCHLABS for 50% off ... Unlock the true power behind modern AI! In this video, we break down


![How Attention Got So Efficient [GQA/MLA/DSA]](https://i.ytimg.com/vi/Y-o545eYjXM/mqdefault.jpg)







![How DeepSeek Rewrote the Transformer [MLA]](https://i.ytimg.com/vi/0VLAoVGf_74/mqdefault.jpg)


