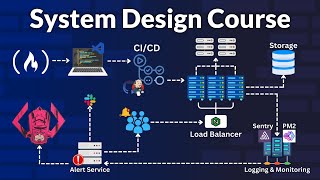
Media Summary: In the AI hype era, most developers just "call an API". This video shows why serving large language models at Sponsored by Databricks Neon → Large language models do not know your private company data. This presentation was recorded at YOW! 2022. Randy Shoup - VP Engineering & Chief ...
System Design Architecting Scalable Llm - Detailed Analysis & Overview
In the AI hype era, most developers just "call an API". This video shows why serving large language models at Sponsored by Databricks Neon → Large language models do not know your private company data. This presentation was recorded at YOW! 2022. Randy Shoup - VP Engineering & Chief ... Learn how URL shorteners like TinyURL and Bitly are designed to handle billions of redirects with low latency. In this step-by-step ... Hey everyone, In this video, I showcase how Large language models are easy to integrate, but operating them reliably in production is a different challenge. In this video, I ...
Code Follow-up: This is how I think through